
基于SoPC的实时说话人识别控制器
来源:电子工程世界 作者:—— 时间:2010-09-13 11:14
1 算法简介
说话人识别系统主要实现建模及识别两方面功能。建模功能提取语音的特征参数并存储起来形成用户模板。识别功能提取语音的特征参数,与模板参数进行匹配,计算其距离。系统框图如图1所示。本文采用改进的DTW(Dynamic Time Warping)算法和LPCC(Linear prediction cepstrum coefficients)特征参数。

1.1 LPCC算法
(1)分帧:语音信号具有短时平稳性[1],因此先将其分帧,再逐帧处理。
(2)有效音检测:有效音检测基于短时能量和短时过门限率两个参数。判决时采取两级判断法:若短时能量高于高门限则判为有声;若低于低门限则判为静音;若介于两者之间,则再判断其过门限率是否高于过门限率门限,若满足则判为有声,否则为静音。
(3)加窗:加窗可滤去不需要的频率分量,同时有利于减少LPCC算法在帧头及帧尾处的误差。本设计采用汉明窗,其表达式如下:

1.2 改进的DTW算法
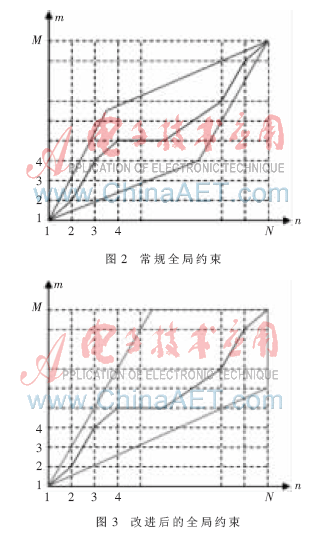
1.2.1 全局约束
图2和图3中,横轴为测试语音参数,纵轴为模板参数,单位为帧。算法以测试语音为基准逐帧进行。如图2,传统的DTW算法中,测试参数长度无法预知时全局约束便无法确定。图3为改进后的DTW,可在未知测试参数长度的情况下进行全局约束,配合帧同步算法,便于算法的实时处理。
1.2.2 局部约束
得到当前距离后便要进行前向路径搜索。n=1指定与m=1匹配。从n=2开始,每个交叉点(n,m)可能的前向路径为(n-1,m)、(n-1,m-1)、(n-1,m-2),选出其中最小者作为当前点(n,m)的前向路径,并将该点的累加距离和加上其当前距离作为当前点的累加距离。最终在n=N处可得到若干个累加距离,选其最小者为最终匹配结果。
1.3 Matlab仿真
1.3.1 实验1:对个性信息的识别能力
实验1的目的在于观察算法对于话者个性信息的识别能力,实验用的语音均为各话者对正确词“开门”的发音,以避免不同单词带来的影响。实验结果如图4所示,系统的等错误率(EER)为0.01,即当错识率为0.01时错拒率也为0.01。

1.3.2 实验2:对语意信息的识别能力
实验2的目的在于观察识别算法对于语意的识别能力,实验用的语音均为同一话者对正确词及错误词的发音,以避免因不同话者带来的影响。如图5所示,在门限为1.25时得到系统的等错误率(EER)为0.01。比较实验1、实验2的结果可知,算法对语义的识别能力和对话者个性信息的识别能力相近。

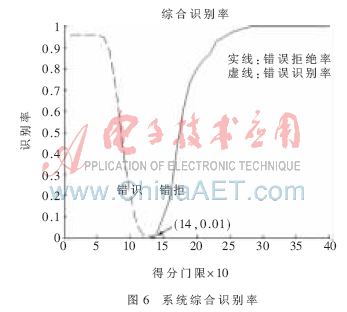
1.3.3 实验3:综合测试
实验3综合考虑了话者的个性信息及语意信息。如图6所示,在门限为1.4时,得到系统的等错误率为0.01,也即此时系统的正确识别率为99%,同时存在1%的错误识别率。
2 SoPC系统构建




