

详解Nvidia定制化64位ARM核心处理器Denver
Nvidia 日前揭开其客制化 64位元ARM核心处理器之神秘面纱,这款代号“Denver”的处理器开发案早在 2011年1月就首度曝光,采用微指令(microcode)架构,具备新一代执行最佳化功能(execution optimizer)。
该款Nvidia预定在今年推出的双核心处理器是Tegra K1的升级,锁定平板装置应用;目前的32位元版本Tegra K1目标应用是Android平台产品,已进驻了宏碁(Acer)的Chromebook、Goole的Project Tango平板装置、小米(Xiaomi)的MyPad,以及Nvidia自家的Shield平板装置。
Nvidia声称,64位元的Tegra K1将可让行动装置具备PC等级的性能,支援游戏、企业应用以及内容创作等;根据该公司表示,基准测试数据显示Denver的效能与英特尔(Intel) Haswell处理器相当,且超越苹果(Apple)的A7系列处理器10~25%。
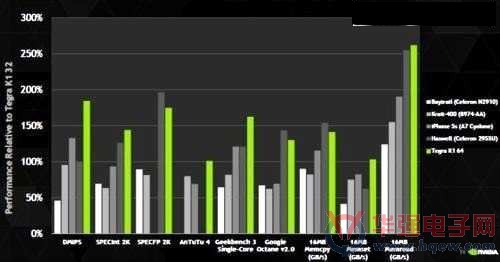
Nvidia 展示的数据为x86架构处理器与32位元ARM处理器的性能测试比较
不过Nvidia并没有提供Denver与ARM的标准64位元A57核心之性能比较;锁定伺服器与网路设备应用,AMD最近开始提供采用A57核心的处理器样品,而Applied Micro也推出了客制化64位元ARM核心的晶片样品。
因为缺乏标准与客制化64位元ARM核心处理器的性能测试比较资料,Nvidia是否能藉Denver提升在行动装置应用领域的地位还不清楚;在该领域,Nvidia还远远落后龙头厂商高通(Qualcomm)。
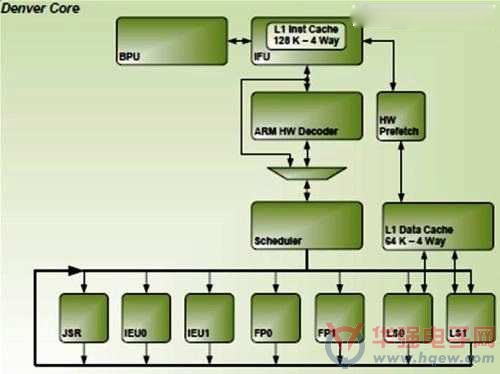
Denver处理器核心架构
Denver每时脉最多能执行7个指令集,最高运作频率2.5GHz,内涵128+64KB L1快取记忆体,以及2MB的16路集合关联(set associative) L2快取记忆体。该处理器最新奇的部分则是取代全乱序执行的最佳化执行功能,可处理包括暂存器重新命名、回路展开(unrolling loops)、断开对false指令归属(breaking false code dependencies),以及移除未用的运算等。
该最佳化程序链结了相关的例行程序(routines),并应用了128MB的主记忆体,在作业系统开机之前进行安全分割(securely partitioned)。Nvidia架构长Darrell Boggs在近日于美国举行的Hot Chip大会上表示:「我们看到最佳化程序可带来两倍以上的速度提升。」
Denver代表Nvidia使用协同处理器核心(companion core)的时代已经结束,这是该公司早期32位元ARM处理器的优势所在,而ARM仍持续寻求混合搭配32位元与64位元核心的解决方案。其他Denver的特点包括重复使用记忆体管线(pipeline)以统整流量,以及可补偿快取记忆体遗漏的预先撷取(pre-fetch)功能。
关注电子行业精彩资讯,关注华强资讯官方微信,精华内容抢鲜读,还有机会获赠全年杂志。
关注方法:添加好友→搜索“华强微电子”→关注
或微信“扫一扫”二维码
